# Database design
# CAP theorem
The CAP theorem says that a distributed system can deliver on only two of three desired characteristics: consistency, availability and partition tolerance.

# Tips

# Normalize Your Data

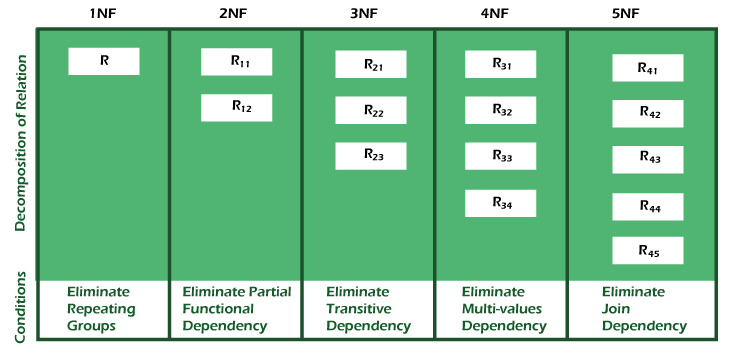
- First Normal Form (1NF): Each column should contain atomic (indivisible) values, and each column should contain values of a single type.
- Second Normal Form (2NF): Every non-key column must depend on the entire primary key, not just part of it. This applies to tables with composite primary keys (a primary key made of multiple columns).
- Third Normal Form (3NF): Every non-key column must depend only on the primary key and nothing else (i.e., no transitive dependencies).
# Use Appropriate Data Types
Choosing the right data types will impact performance and storage efficiency. Always:
- Use the smallest data type that can hold your data.
- Avoid using
TEXTorBLOBunless absolutely necessary. - Be mindful of precision requirements for
numeric datatypes. - Use
DATEorTIMESTAMPfor date/time data instead of strings.
# Indexing Strategy
Indexes will improve query performance but can also slow down INSERT, UPDATE, and DELETE operations if overused. Develop a balanced indexing strategy:
- Index columns are often used in
WHERE,JOIN, andORDER BYclauses. - Avoid indexing columns that are often updated.
- Use composite indexes for queries involving many columns. Example: Add an index if you do lookups often for the email column.
# Use Constraints and Relationships
Enforce data integrity and relationships through constraints:
- Use primary keys to identify rows uniquely.
- Define foreign keys to enforce referential integrity between tables.
- Define unique constraints for columns that require unique values.
- Apply check constraints to enforce domain rules at the database level.
Example: Use
NOT NULLconstraints to ensure critical columns are always filled.
# Partition Large Tables
- Horizontal Partitioning: Split a table into many tables containing the same columns but different rows.
- Vertical Partitioning: Split a table into many tables containing different columns. Example: Separate infrequently accessed columns into a different table to reduce the size of the main table.
# DB Isolation options
Data isolation ensures that modules are independent and loosely coupled.

A modular monolith has strict rules for data integrity:
- Each module can only access its own tables
- No sharing of tables or objects between modules
- Joins are only allowed between tables of the same module
# Database Normalization
Database Normalization is a design step which eliminates redundant data stored in form of large monolithic tables making the overall query execution simpler.
The main purpose of this normalized data is logical storage of data using relationships between the tables. As originally proposed by Edgar Codd, there are six steps involved in the overall process from 1NF to 6NF as described below. Most modern databases follow a standard upto the 4NF step.
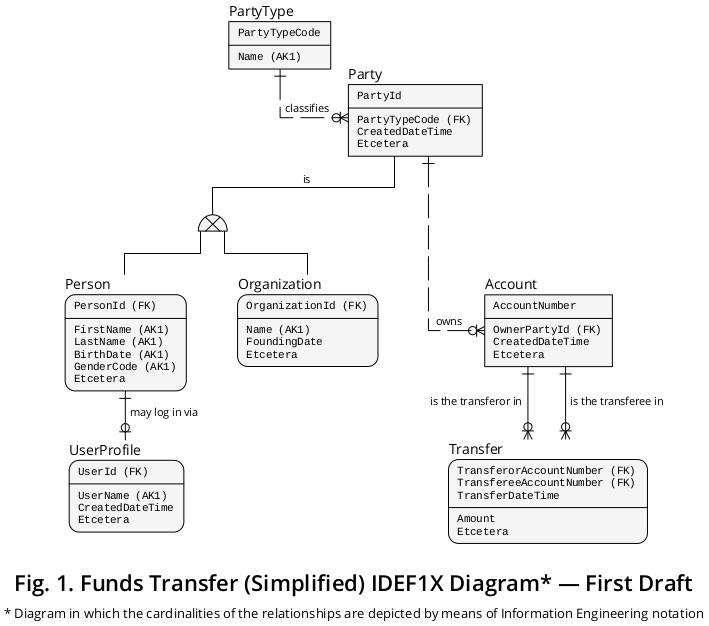
# Polymorphic DB Table Design
Look at Example Person and Organization Example (opens new window)
source:
Key takeaways:
- "As demonstrated, Person and Organization are depicted as mutually exclusive subtypes of Party."
- "The Party supertype holds a discriminator (i.e., PartyTypeCode) and all the properties (or attributes) that are common to its subtypes, which, in turn, have the properties that apply to each of them."
Result DB diagram. Pay attention to how the polymorphic relationships resolved using this design:
- Person is-a Party
- Organization is-a Party
- PartyTypeCode is the discriminator
See more:
- 3 ways to implement class hierarchies in relational databases (opens new window)
- Single Table Inheritance (opens new window)
- Class Table Inheritance (opens new window)
- Concrete Table Inheritance (opens new window)
# Entity-Attribute-Value (EAV)
Entity-Attribute-Value (EAV) is a database design paradigm that is particularly effective for handling dynamic and unpredictable data structures. Instead of creating a fixed schema with predefined columns, EAV stores data in a more flexible manner:
- Entity: Represents a subject or object.
- Attribute: Describes a property or characteristic of an entity.
- Value: The specific data associated with an attribute for a given entity.
# How EAV Works
In an EAV database, there are typically three main tables:
- Entity Table: Stores unique identifiers for each entity.
- Attribute Table: Contains a list of all possible attributes that can be associated with entities.
- Value Table: Relates entities, attributes, and their corresponding values.
# Examples
Simple DB Design 
Magento DB Design 
# Pros & cons
Advantages:
- Flexibility: New attributes like "PreferredColor" or "LastLoginDate" can be added without modifying the database schema.
- Scalability: Handles large datasets with varying customer information efficiently.
- Data Mining: Ideal for analyzing customer preferences, purchase behavior, and other patterns.
Disadvantages :
- Query Performance: Queries that involve multiple attributes can be less efficient than in a traditional relational database, especially for large datasets.
- Complexity: Managing the EAV model can be more complex than traditional relational databases, requiring careful consideration of indexing and query optimization.
# Metadata DB Table Design
Wordpress database is a great example
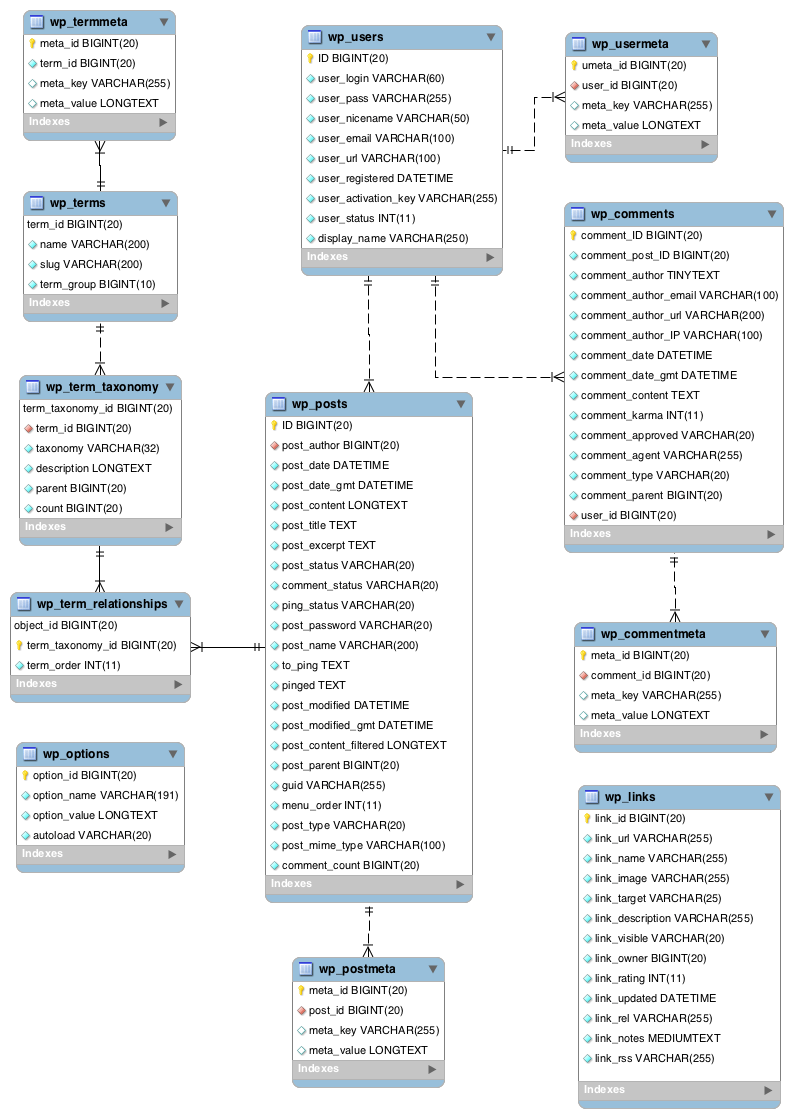
Another one (opens new window)
# Thoughts on Foreign Keys
At GitHub we do not use foreign keys, ever, anywhere.
- FKs are in your way to shard your database. Your app is accustomed to rely on FK to maintain integrity, instead of doing it on its own. It may even rely on FK to cascade deletes (shudder). When eventually you want to shard or extract data out, you need to change & test the app to an unknown extent.
- FKs are a performance impact. The fact they require indexes is likely fine, since those indexes are needed anyhow. But the lookup made for each
insert/deleteis an overhead. - FKs don't work well with online schema migrations.
Read more: