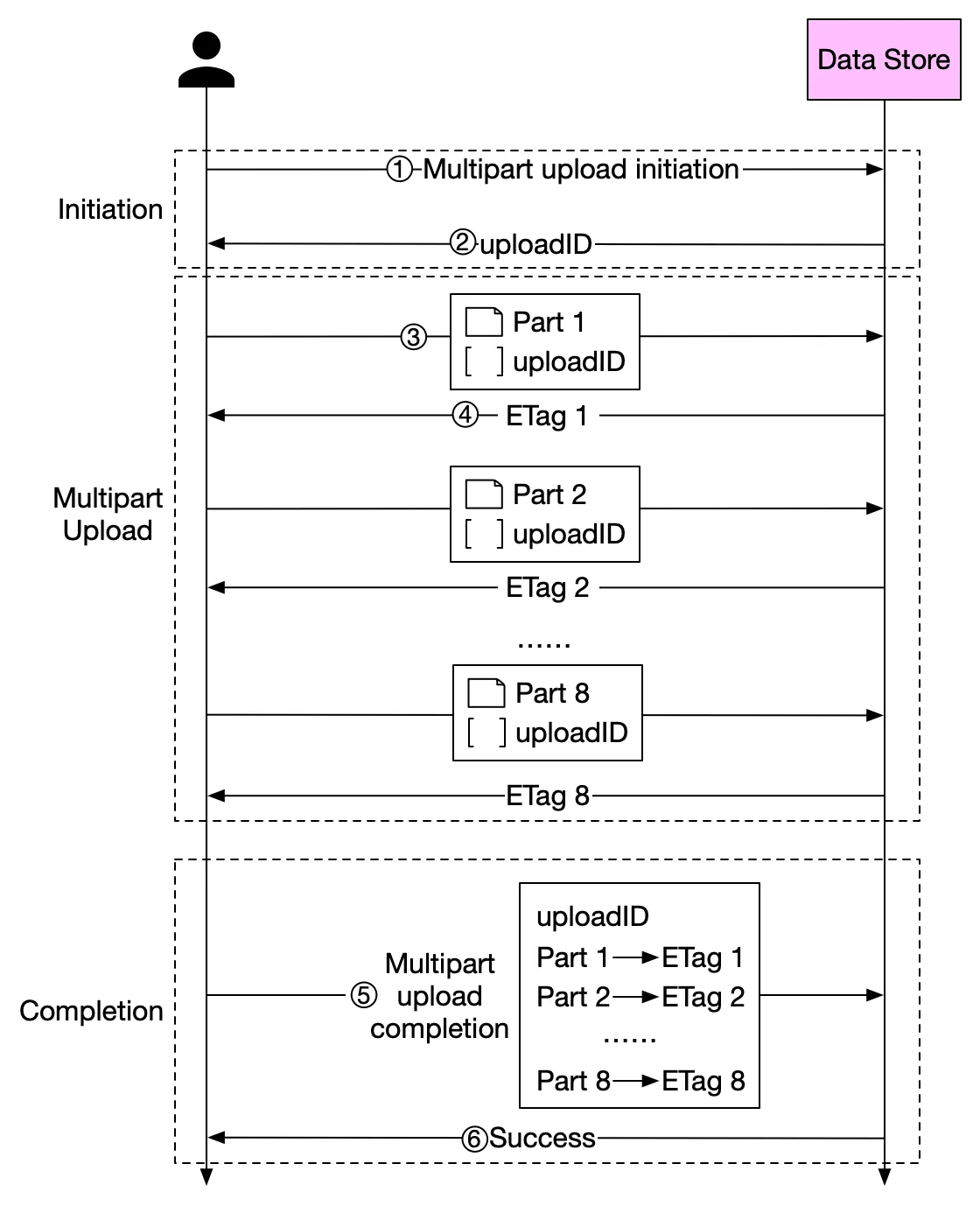
# Upload large file
Example Repo (opens new window)
# FE Implementation
You can use the JavaScript Blob object (opens new window) to slice (Blob.prototype.slice) large files into smaller chunks and transfer concurrently these to the server to be merged together. This has the added benefit of being able to pause/resume downloads and indicate progress.
Due to concurrency, the order of transmission to the server may change, so we also need to record the order for each chunk.
# BE (Node) Implementation
Endpoints: upload/:id/part, upload/:id/merge
# Accept chunks
Node package multiparty (opens new window) for parsing incoming HTML form data.
When accepting file chunks, you need to create a folder for temporarily storing chunks and the filename as a suffix.
└── upload-files/
└── upload-id/
├── chunk-1
├── chunk-2
└── chunk-3
async handleFormData(req, res) {
const multipart = new multiparty.Form();
multipart.parse(req, async (err, fields, files) => {
if (err) {
console.error(err);
res.status = 500;
res.end("process file chunk failed");
return;
}
const [chunk] = files.chunk;
const [hash] = fields.hash;
const [fileHash] = fields.fileHash;
const [filename] = fields.filename;
const filePath = path.resolve(
UPLOAD_DIR,
`${fileHash}${extractExt(filename)}`
);
const chunkDir = getChunkDir(fileHash);
const chunkPath = path.resolve(chunkDir, hash);
// return if file is exists
if (fse.existsSync(filePath)) {
res.end("file exist");
return;
}
// return if chunk is exists
if (fse.existsSync(chunkPath)) {
res.end("chunk exist");
return;
}
// if chunk directory is not exist, create it
if (!fse.existsSync(chunkDir)) {
await fse.mkdirs(chunkDir);
}
// use fs.move instead of fs.rename
// https://github.com/meteor/meteor/issues/7852#issuecomment-255767835
await fse.move(chunk.path, path.resolve(chunkDir, hash));
res.end("received file chunk");
});
}
# Merge chunks
- use
fs.createWriteStreamto create a writable stream - merge the transmission into the target file.
Note:
- delete the chunk after each merge,
- delete the chunk folder after all the chunks are merged.
async handleMerge(req, res) {
const data = await resolvePost(req);
const { fileHash, filename, size } = data;
const ext = extractExt(filename);
const filePath = path.resolve(UPLOAD_DIR, `${fileHash}${ext}`);
await mergeFileChunk(filePath, fileHash, size);
res.end(
JSON.stringify({
code: 0,
message: "file merged success"
})
);
}
const getChunkDir = fileHash => path.resolve(UPLOAD_DIR, `chunkDir_${fileHash}`);
const mergeFileChunk = async (filePath, fileHash, size) => {
const chunkDir = getChunkDir(fileHash);
const chunkPaths = await fse.readdir(chunkDir);
// sort by chunk index
// otherwise, the order of reading the directory may be wrong
chunkPaths.sort((a, b) => a.split("-")[1] - b.split("-")[1]);
// write file concurrently
await Promise.all(
chunkPaths.map((chunkPath, index) =>
pipeStream(
path.resolve(chunkDir, chunkPath),
// create write stream at the specified starting location according to size
fse.createWriteStream(filePath, {
start: index * size
})
)
)
);
// delete chunk directory after merging
fse.rmdirSync(chunkDir);
}
// write to file stream
const pipeStream = (path, writeStream) =>
new Promise(resolve => {
const readStream = fse.createReadStream(path);
readStream.on("end", () => {
fse.unlinkSync(path);
resolve();
});
readStream.pipe(writeStream);
});
# With AWS SDK to S3?