# High-water mark
The high-water mark is an index into the log file that records the last log entry that is known to have successfully replicated to a Quorum of followers. The leader also passes on the high-water mark to its followers during its replication. All servers in the cluster should only transmit data to clients that reflects updates that are below the high-water mark.
# Sequence of operations
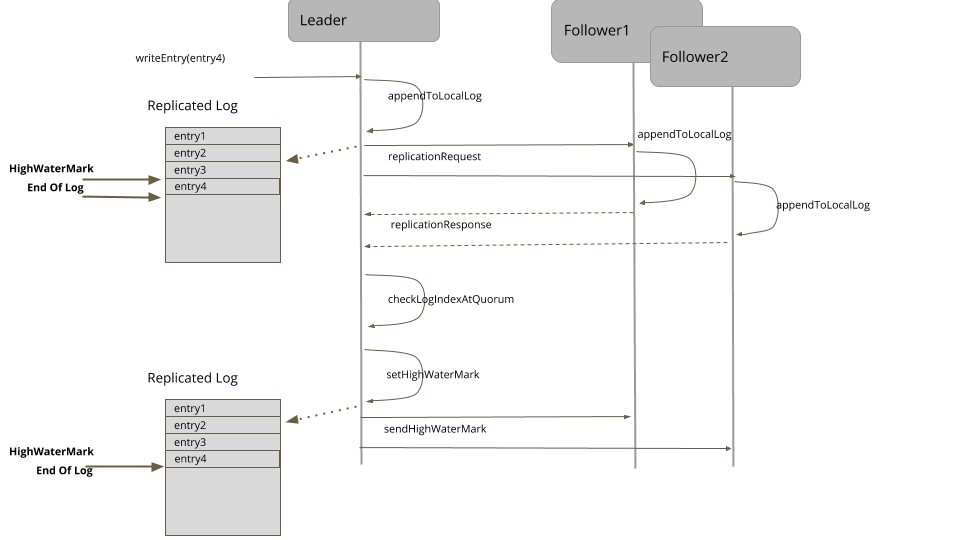
For each log entry, the leader appends it to its local write ahead log, and then sends it to all the followers.
Leader ReplicationLog.java
private Long appendAndReplicate(byte[] data) {
Long lastLogEntryIndex = appendToLocalLog(data);
replicateOnFollowers(lastLogEntryIndex);
return lastLogEntryIndex;
}
private void replicateOnFollowers(Long entryAtIndex) {
for (final FollowerHandler follower : followers) {
replicateOn(follower, entryAtIndex); //send replication requests to followers
}
}
The followers handle the replication request and append the log entries to their local logs. After successfully appending the log entries, they respond to the leader with the index of the latest log entry they have. The response also includes the current Generation Clock of the server.
Follower
private ReplicationResponse appendEntries(ReplicationRequest replicationRequest) {
List<WALEntry> entries = replicationRequest.getEntries();
entries.stream()
.filter(e -> !wal.exists(e))
.forEach(e -> wal.writeEntry(e));
return new ReplicationResponse(SUCCEEDED, serverId(), replicationState.getGeneration(), wal.getLastLogIndex());
}
The Leader keeps track of log indexes replicated at each server, when responses are received.
logger.info("Updating matchIndex for " + response.getServerId() + " to " + response.getReplicatedLogIndex());
updateMatchingLogIndex(response.getServerId(), response.getReplicatedLogIndex());
var logIndexAtQuorum = computeHighwaterMark(logIndexesAtAllServers(), config.numberOfServers());
var currentHighWaterMark = replicationState.getHighWaterMark();
if (logIndexAtQuorum > currentHighWaterMark && logIndexAtQuorum != 0) {
applyLogEntries(currentHighWaterMark, logIndexAtQuorum);
replicationState.setHighWaterMark(logIndexAtQuorum);
}
The high-water mark can be calculated by looking at the log indexes of all the followers and the log of the leader itself, and picking up the index which is available on the majority of the servers.
Long computeHighwaterMark(List<Long> serverLogIndexes, int noOfServers) {
serverLogIndexes.sort(Long::compareTo);
return serverLogIndexes.get(noOfServers / 2);
}
The leader propagates the high-water mark to the followers either as part of the regular HeartBeat or as separate requests. The followers then set their high-water mark accordingly.
Any client can read the log entries only till the high-water mark. Log entries beyond the high-water mark are not visible to clients as there is no confirmation that the entries are replicated, and so they might not be available if the leader fails, and some other server is elected as a leader.
public WALEntry readEntry(long index) {
if (index > replicationState.getHighWaterMark()) {
throw new IllegalArgumentException("Log entry not available");
}
return wal.readAt(index);
}
# Log Truncation
When a server joins the cluster after crash/restart, there is always a possibility of having some conflicting entries in its log. So whenever a server joins the cluster, it checks with the leader of the cluster to know which entries in the log are potentially conflicting. It then truncates the log to the point where entries match with the leader,and then updates the log with the subsequent entries to ensure its log matches the rest of the cluster.
Consider the following example. The client sends requests to add four entries in the log. The leader successfully replicates three entries, but fails after adding entry4 to its own log. One of the followers is elected as a new leader and accepts more entries from the client. When the failed leader joins the cluster again, it has entry4 which is conflicting. So it needs to truncate its log till entry3, and then add entry5 to match the log with the rest of the cluster.
Any server which restarts or rejoins the cluster after a pause, finds the new leader. It then explicitly asks for the current high-water mark, truncates its log to high-water mark, and then gets all the entries beyond high-water mark from the leader. Replication algorithms like RAFT have ways to find out conflicting entries by checking log entries in its own log with the log entries in the request. The entries with the same log index, but at lower Generation Clock, are removed.
void maybeTruncate(ReplicationRequest replicationRequest) {
replicationRequest.getEntries().stream()
.filter(entry -> wal.getLastLogIndex() >= entry.getEntryIndex() &&
entry.getGeneration() != wal.readAt(entry.getEntryIndex()).getGeneration())
.forEach(entry -> wal.truncate(entry.getEntryIndex()));
}
A simple implementation to support log truncation is to keep a map of log indexes and file position. Then the log can be truncated at a given index, as following:
class WALSegment...
public synchronized void truncate(Long logIndex) throws IOException {
var filePosition = entryOffsets.get(logIndex);
if (filePosition == null) throw new IllegalArgumentException("No file position available for logIndex=" + logIndex);
fileChannel.truncate(filePosition);
truncateIndex(logIndex);
}
private void truncateIndex(Long logIndex) {
entryOffsets.entrySet().removeIf(entry -> entry.getKey() >= logIndex);
}
# Examples
- All the consensus algorithms use the concept of high-water mark to know when to apply the proposed state mutations. e.g. In the RAFT consensus algorithm, high-water mark is called 'CommitIndex'.
- In Kafka replication protocol, there is a separate index maintained called 'high-water mark'. Consumers can see entries only until the high-water mark.
- Apache BookKeeper has a concept of 'last add confirmed', which is the entry which is successfully replicated on quorum of bookies.