# Fault Tolerance Patterns
Fault Tolerance aka Resilience Patterns
The Fault Tolerant means the ability of an architecture to survive (tolerate) when an environment misbehaves by taking corrective actions, e.g, surviving a server crash or preventing a misbehaving API from bringing down the whole system, etc.
The Fault Resilience is probably the capacity to recover from these type of scenarios quickly.
After further reading of Netflix blogs and wikis, it seemed the terms Fault Resilience and Fault Tolerant were used interchangeably.
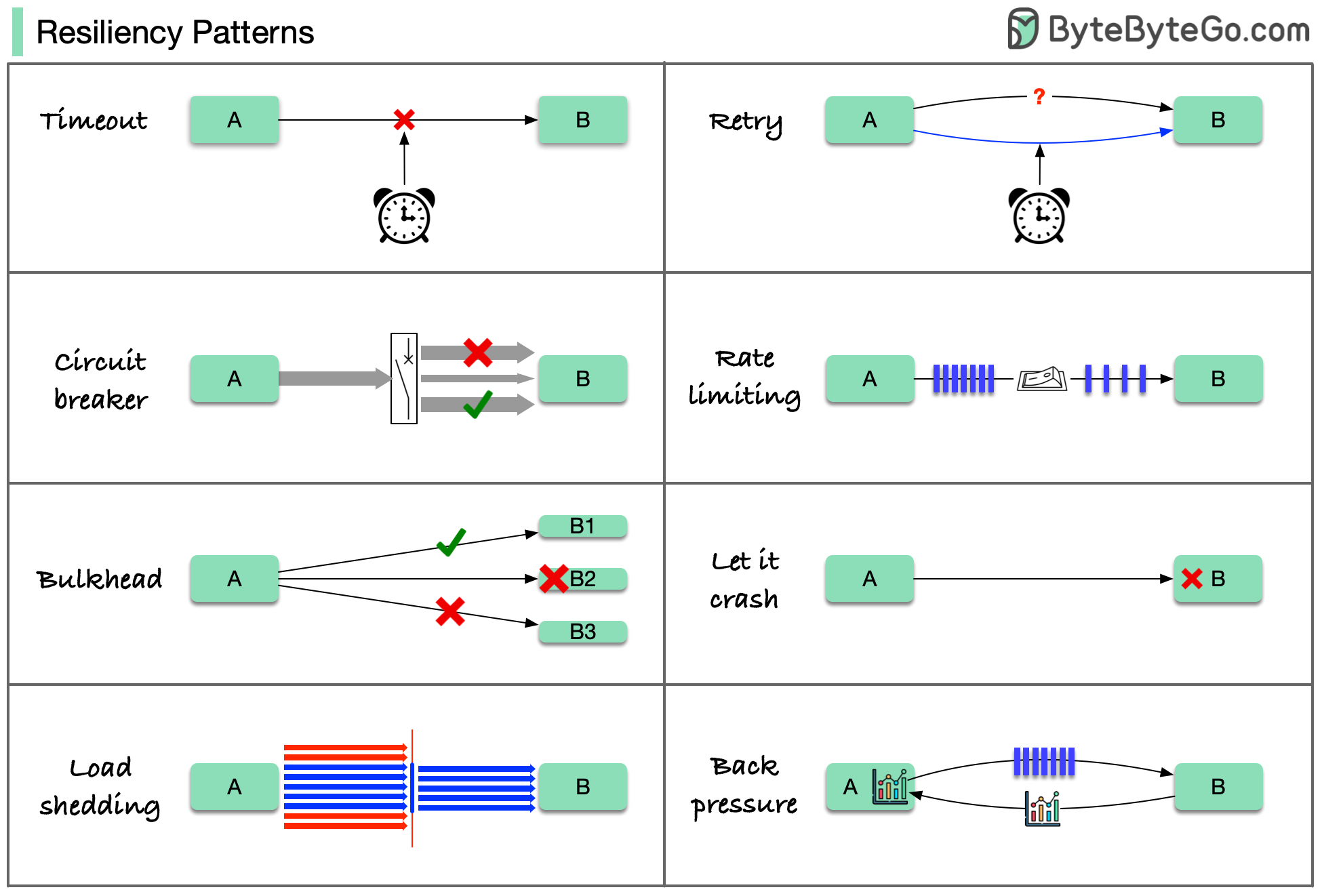
# Cheatsheet

# 2 metrics for Resilient system

Error budgetting
Allowable Downtime = Total tiem & (1 - Uptime %)
Mean time to Recovery (MTTR)
MTTR = Total Downtime / Number of incidents
# Pattern List
There are various resilience patterns that can be applied to microservices, categorized by their impact on downstream and upstream components. Let's explore some of these patterns in detail.
| Pattern | Impact on |
|---|---|
| Retry (exponential backoff, retry amplification) | Downstream / Upstream |
| Bulkhead | Downstream |
| Circuit Breaker | Downstream |
| Timeout | Downstream |
| Rate limiting | Upstream |
| Load leveling | Upstream |
| Load shedding | Upstream |
| Fallback | Upstream |
| Failover | Upstream |
| Stateless |
These patterns are usually not used alone. To apply them effectively, we need to understand why we need them, how they work, and their limitations.
# Shopify case study

# Prevent misuse & overload

# Anti-corruption layer

# Retry patterns

# Fallback
When the the service request fails after retry, we need an alternative response to the request. Fallback provides an alternative solution during a service request failure. When the circuit breaker trips and the circuit is open, a fallback logic can be started instead. The fallback logic typically does little or no processing, and return value. Fallback logic must have little chance of failing, because it is running as a result of a failure to begin with.
In this approach, the client process performs fallback logic when a request fails, such as returning cached data or a default value. This is an approach suitable for queries, and is more complex for updates or commands.
# Deadlines / distributed timeouts
// TODO
# Asynchronous communication
Use Asynchronous communication (for example, message-based communication) across internal microservices
# Stateless Services
To make sure our services are scalable, we need to make sure we build them in a stateless manner. By stateless, we mean that the service does not retain any state from the previous calls and treats every request as a fresh, new one. The advantage this approach gives us is that we can easily create replicas of the same service and make sure it does not matter which service instance is handling the request.
# Correlation ID
In a typical microservices-based application, several services span different systems, possibly separated by large geographical distances. This means each service must log useful and meaningful data that specifies what it has been doing and details any failures. This requires a third microservices resiliency pattern geared towards service tracking.
A correlation ID pattern creates an identifier for each individual request. This can help you track the complete flow of each HTTP request through all communication channels. You can set the correlation ID as part of the HTTP request header and include it in every log message, which will help you to quickly find errors, warnings and relevant debug messages.
While a correlation ID will illustrate the flow of a request from the source to the destination, a log aggregator pulls together the logs from all your microservices for easier search and analysis.
Detail: 3 microservices resiliency patterns for better reliability (opens new window)
# Refs
- 5 patterns to make your microservice fault-tolerant (opens new window)
- Guide to Microservices Resilience Patterns (opens new window) https://newsletter.grokking.org/p/172-mo-hinh-vach-ngan-bulkhead-pattern-trong-thi-t-k-microservice-617401